利用php下载火车头内容标签图片,并自定义目录及图片名,其实火车头都能自定义图片下载,纯无聊写的代码。供学习参考。
将代码复制别存到Plugins目录,并命名为downimg.php,如下图所示,启用插件。
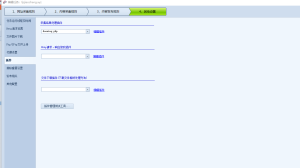
标签里加入图片目录、图片名、设置cookie(有些图片需要有cookie才能采集到,就有用。)
<?php // 关闭错误报告 error_reporting(0); // 设置响应头内容类型为HTML,字符编码为UTF-8 header("Content-type: text/html; charset=utf-8"); // 初始化cookie处理 if (isset($_COOKIE['custom_settings'])) { // 解码cookie中的设置 $cookieSettings = json_decode($_COOKIE['custom_settings'], true); // 检查JSON解码是否成功 if (json_last_error() === JSON_ERROR_NONE) { // 将cookie设置合并到标签数组中 foreach ($cookieSettings as $key => $value) {
if (!isset($LabelArray[$key])) {
$LabelArray[$key] = $value;
}
}
}
}
// 处理内容字段中的图片下载
if (isset($LabelArray['内容'])) {
$LabelArray['内容'] = download_images($LabelArray['内容'], $LabelArray);
}
/**
* 下载远程图片到本地
* @param string $content 包含图片的HTML内容
* @param array $LabelArray 标签数组(包含设置)
* @return string 处理后的HTML内容
*/
function download_images($content, $LabelArray) {
// 设置图片下载目录
$download_dir = isset($LabelArray['图片目录']) && !empty($LabelArray['图片目录'])
? rtrim($_SERVER['DOCUMENT_ROOT'], '/') . '/' . trim($LabelArray['图片目录'], '/') . '/'
: rtrim($_SERVER['DOCUMENT_ROOT'], '/') . '/images/fx/';
// 设置图片基础URL
$base_url = isset($LabelArray['图片目录']) && !empty($LabelArray['图片目录'])
? '/' . trim($LabelArray['图片目录'], '/') . '/'
: '/images/fx/';
// 检查并创建目录(如果不存在)
if (!file_exists($download_dir)) {
if (!mkdir($download_dir, 0755, true) && !is_dir($download_dir)) {
// 记录目录创建错误
error_log("[DIR ERROR] 无法创建目录: " . print_r(error_get_last(), true));
return $content;
}
}
// 匹配HTML中的所有img标签
preg_match_all(
'/<img\b[^>]*?\bsrc\s*=\s*(["\'])((?:https?:)?\/\/[^"\'\s>]+?\.(?:jpe?g|png|gif|webp|bmp)(?:\?[^"\'\s>]*)?)\1[^>]*>/i',
$content,
$matches,
PREG_SET_ORDER
);
$replacements = []; // 存储替换内容
$image_counter = 1; // 图片计数器
// 处理每个匹配到的图片
foreach ($matches as $match) {
$full_match = $match[0]; // 完整img标签
$quote = $match[1]; // 使用的引号类型
$original_url = html_entity_decode($match[2]); // 解码HTML实体后的原始URL
// 跳过已经本地化的图片
if (strpos($original_url, $base_url) === 0 || strpos($original_url, '/images/fx/') !== false) {
continue;
}
// 规范化URL(处理无协议和相对协议的情况)
if (strpos($original_url, '//') === 0) {
$original_url = 'https:' . $original_url;
} elseif (!preg_match('/^https?:/i', $original_url)) {
continue; // 跳过非http(s)协议的URL
}
// 下载图片内容(带重试机制)
$file_content = false;
$retry = 0;
$max_retries = 2;
while ($retry < $max_retries && !$file_content) { $file_content = download_file($original_url); if (!$file_content) { $retry++; usleep(500000); // 重试前等待0.5秒 } } // 下载失败则跳过 if (!$file_content) { error_log("下载失败: {$original_url}"); continue; } // 获取文件扩展名 $file_extension = strtolower(pathinfo(parse_url($original_url, PHP_URL_PATH), PATHINFO_EXTENSION)); // 生成新文件名 if (isset($LabelArray['图片名']) && !empty($LabelArray['图片名'])) { $new_filename = $LabelArray['图片名']; // 多张图片时添加序号 if (count($matches) > 1) {
$new_filename .= '_' . str_pad($image_counter, 2, '0', STR_PAD_LEFT);
}
$new_filename .= '.' . $file_extension;
$image_counter++;
} else {
// 生成随机文件名
$new_filename = time() . '_' . substr(str_shuffle("abcdefghijklmnopqrstuvwxyz"), 0, 6) . '.' . $file_extension;
}
$save_path = $download_dir . $new_filename;
// 保存图片文件
if (file_put_contents($save_path, $file_content)) {
// 构建新的图片URL
$new_url = $base_url . $new_filename;
// 替换img标签中的src属性
$new_img_tag = preg_replace(
'/(src\s*=\s*["\'])(?:https?:)?\/\/[^"\'\s>]+?\.(?:jpe?g|png|gif|webp|bmp)(?:\?[^"\'\s>]*)?(["\'])/i',
'$1' . $new_url . '$2',
$full_match
);
$replacements[$full_match] = $new_img_tag;
}
}
// 执行替换操作
if (!empty($replacements)) {
$content = strtr($content, $replacements);
// 验证是否还有远程图片未替换
if (preg_match('/src\s*=\s*["\']https?:\/\//i', $content)) {
error_log("[警告] 仍有远程图片未替换: " . substr($content, 0, 500));
}
}
return $content;
}
/**
* 下载文件函数
* @param string $url 文件URL
* @return mixed 文件内容或false
*/
function download_file($url) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_TIMEOUT, 15);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36');
// 设置Referer和HTTP头
curl_setopt($ch, CURLOPT_REFERER, 'https://fpjiaocheng.xyz');
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'Accept: image/webp,image/apng,image/*,*/*;q=0.8',
'Accept-Language: zh-CN,zh;q=0.9,en;q=0.8',
]);
// 添加cookie支持
if (!empty($_COOKIE)) {
$cookies = [];
foreach ($_COOKIE as $name => $value) {
$cookies[] = $name . '=' . $value;
}
curl_setopt($ch, CURLOPT_COOKIE, implode('; ', $cookies));
}
$data = curl_exec($ch);
$httpcode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
// 检查HTTP状态码
if ($httpcode != 200) {
error_log("下载失败 HTTP {$httpcode}: {$url}");
return false;
}
return $data;
}
// 设置cookie(如果需要)
if (isset($LabelArray['设置cookie'])) {
$cookieSettings = [];
if (isset($LabelArray['图片目录'])) {
$cookieSettings['图片目录'] = $LabelArray['图片目录'];
}
if (isset($LabelArray['图片名'])) {
$cookieSettings['图片名'] = $LabelArray['图片名'];
}
// 设置30天有效期的cookie
if (!empty($cookieSettings)) {
setcookie('custom_settings', json_encode($cookieSettings), time() + 86400 * 30, '/');
}
}
// 输出序列化后的标签数组
echo serialize($LabelArray);
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论(0)